字库移植
本章节会解析字库部分代码,并介绍如何使用开发者的字库替换替换 HoneyGUI 的原生字库,或者加入定制化功能。
点阵字库移植
字形加载
文本编码转换
在文件 font_mem.c ,函数 gui_font_get_dot_info() 中, process_content_by_charset() 会解析文本控件的文本内容,
并保存为 unicode (UTF-32) 储存到 unicode_buf ,Unicode 数量作为返回值输入 unicode_len 。
uint32_t *unicode_buf = NULL;
uint16_t unicode_len = 0;
unicode_len = process_content_by_charset(text->charset, text->content, text->len, &unicode_buf);
if (unicode_len == 0)
{
gui_log("Warning! After process, unicode len of text: %s is 0!\n", text->base.name);
text->font_len = 0;
return;
}
process_content_by_charset() 的具体实现请查阅 draw_font.c 。
Note
解析过程支持 UTF-8、UTF-16 和 UTF-32。
后续会根据 unicode_buf 中的 Unicode 信息索引字库中的文本数据。
编码转换前后都可以进行小语种的文本编码转换,例如阿拉伯语的字符拼接及其他对 Unicode 进行计算的部分。如果在后面进行转换,需要同步修改 unicode_len 。
Note
unicode_len 的单位是字节,而非字符数量。
字库索引
在文件 font_mem.c ,函数 gui_font_get_dot_info() 中,解析得到 Unicode 之后,会使用 Unicode 去文本控件指定的字库中索引字形信息。
由于字库工具具有 crop 属性,以及两种索引模式,因此在使用 unicode 在字库文件中寻找文本数据以及点阵数据时,使用了不同的解析代码。
字库解析代码的目的是填充 chr 结构体数组,其结构如下:
typedef struct
{
uint32_t unicode;
int16_t x;
int16_t y;
int16_t w;
int16_t h;
uint8_t char_y;
uint8_t char_w;
uint8_t char_h;
uint8_t *dot_addr;
uint8_t *buf;
void *emoji_img;
} mem_char_t;
每个成员的含义如下:
Unicode是点阵文本的 Unicode,使用 UTF-32LE 格式表达;x是点阵文本边框左上角的 X 坐标,排版时确定,用来确定文本绘制坐标;y是点阵文本边框左上角的 Y 坐标,排版时确定,用来确定文本绘制坐标;w是点阵数据中该字符的数据位宽,由于存在字节对齐以及压缩的特性,因此该值并不总等于字号;h是点阵文本的高度,恒等于字号,用来限制基础绘制区域以及多行排版;char_y是字符的上方空白行数,代表文本点阵图中最上方像素点 Y 坐标与上边框的距离,用来限制绘制区域;char_w是字符的像素宽度,代表文本边框最左侧(起始点)与文本最右侧像素 X 方向坐标差值,绘制时使用该值限制绘制区域,排版时使用该值代表文本宽度;char_h是字符的像素高度,代表文本点阵图中最下方像素点 Y 坐标与上边框的距离,用来限制绘制区域;char_h减去char_y的数值为点阵的实际像素高度;dot_addr是该文本对应的点阵数据的起始地址;emoji_img是 Emoji 图片对应的控件指针,未使用 Emoji 功能时,该值为空;
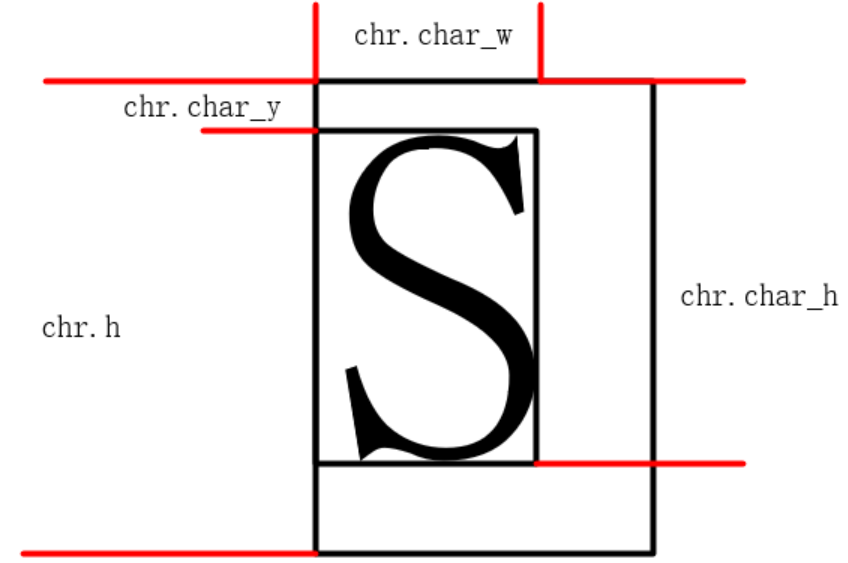
字形示例
在字库索引阶段,会填充所有 chr 的除 x y 坐标以外的全部成员,为下一步排版做准备。
Note
由于不同模式下的数据存储规则有差异,绘制区域也有差异。
例如 char_y 与 char_h 仅在 crop=1 并且 index_method=0 时才生效。
由于该阶段会使用 Unicode 去查找点阵文本的宽度信息以及点阵数据指针,因此最好在这一步骤之前完成 Unicode 级别的变形文本的融合过程,例如阿拉伯语的拼接,而泰语的字形融合则属于排版阶段的图形融合。
如果使用自己的定制字库进行移植,可以利用定制字库的信息填充至 chr 数据结构中,在后续的排版和绘制阶段,使用默认部分。
排版
文本控件支持多种不同的排版模式。
具体的排版功能在文件 font_mem.c 的函数 gui_font_mem_layout() 中,每种排版模式具有不同的排版逻辑,但是都依赖于字形信息 chr 和文本控件提供的边框信息 rect 。
rect 结构体数组结构如下:
typedef struct gui_text_rect
{
int16_t x1;
int16_t y1;
int16_t x2;
int16_t y2;
int16_t xboundleft;
int16_t xboundright;
int16_t yboundtop;
int16_t yboundbottom;
} gui_text_rect_t;
rect 为控件层传入的控件显示范围,其中 x1 和 x2 分别代表左边框和右边框的 X 坐标, y1 和 y2 分别代表上边框和下边框的 Y 坐标,其数值是内部控件计算生成,依赖控件创建时的位置和大小。
通过 rect 的四个坐标计算出 rect_w 和 rect_h 。
四组 bound 值是滚动文本控件 scroll_text 用来处理显示边界的,文本控件 text 暂时没有使用。
开发者可以根据需求,添加新的排版模式。
通过 gui_text_wordwrap_set() 使能了英文单词换行功能(wordwrap)后,多行排版会增加英文单词的换行规则,防止英文单词的截断。
字符绘制
点阵字符的绘制代码位于 font_mem.c 中的 rtk_draw_unicode 中。
可以指定文本控件开启矩阵运算功能以适配文本缩放效果,这部分字符的绘制代码位于 font_mem_matrix.c 中的 rtk_draw_unicode_matrix 中。
可以指定文本控件开启转图片功能,将文本转化成图片,可以实现复杂特效,这部分字符的绘制代码位于 font_mem_img.c 中的 gui_font_bmp2img_one_char 中。
字符绘制阶段不涉及任何排版信息,只会读取字形信息,并绘制到屏幕缓存中。
每个字的绘制都会使用控件边框、屏幕的边框以及当前字符的边框三重限制绘制区域。
如果开发者想要使用特殊的字库进行绘制,需要修改点阵数据解析代码,并将像素绘制到屏幕缓存中。
API
Defines
-
FONT_MALLOC_PSRAM(x) gui_malloc(x)
-
FONT_FREE_PSRAM(x) gui_free(x)
-
FONT_FILE_BMP_FLAG 0x01
Functions
-
uint8_t gui_font_mem_init(uint8_t *font_bin_addr)
Initialize the character binary file and store the font and corresponding information in the font list.
- Parameters
font_bin_addr -- Binary file address of this font type.
- Returns
Font library index.
-
uint8_t gui_font_mem_init_ftl(uint8_t *font_bin_addr)
Initialize the character binary file and store the font and corresponding information in the font list.
- Parameters
font_bin_addr -- Font file address.
- Returns
Font library index.
-
uint8_t gui_font_mem_init_fs(uint8_t *font_bin_addr)
Initialize the character binary file and store the font and corresponding information in the font list.
- Parameters
font_bin_addr -- Font file address.
- Returns
Font library index.
-
uint8_t gui_font_mem_init_mem(uint8_t *font_bin_addr)
Initialize the character binary file and store the font and corresponding information in the font list.
- Parameters
font_bin_addr -- Font file address.
- Returns
Font library index.
-
uint8_t gui_font_mem_delate(uint8_t *font_bin_addr)
Destroy this font type in font list.
- Parameters
font_bin_addr -- Font file address.
- Returns
Font library index.
-
void gui_font_mem_load(gui_text_t *text, gui_text_rect_t *rect)
Preprocessing of bitmap fonts using internal engines.
- Parameters
text -- Widget pointer.
rect -- Widget boundary.
-
void gui_font_mem_draw(gui_text_t *text, gui_text_rect_t *rect)
Drawing of bitmap fonts using internal engine.
- Parameters
text -- Widget pointer.
rect -- Widget boundary.
-
void gui_font_mem_unload(gui_text_t *text)
Post-processing work for drawing bitmap fonts using internal engines.
- Parameters
text -- Widget pointer.
-
void gui_font_mem_destroy(gui_text_t *text)
GUI_FONT_SRC_BMP text widget destroy function.
- Parameters
text -- Widget pointer.
-
uint32_t gui_get_mem_char_width(void *content, void *font_bin_addr, TEXT_CHARSET charset)
Get the pixel width of the text in the current font file.
- Parameters
content -- Text pointer.
font_bin_addr -- Font file address.
charset -- Text encoding format.
- Returns
Character width.
-
uint32_t gui_get_mem_utf8_char_width(void *content, void *font_bin_addr)
Get the pixel width of the utf-8 text in the current font file.
- Parameters
content -- Text pointer.
font_bin_addr -- Font file address.
- Returns
Character width.
-
uint8_t get_fontlib_by_size(uint8_t font_size)
Get the font library index by size.
- Parameters
font_size -- Font size.
- Returns
Font library index.
-
uint8_t get_fontlib_by_name(uint8_t *font_file)
Get the font library index by name.
- Parameters
font_file -- Font file.
- Returns
Font library index.
-
void gui_font_mem_layout(gui_text_t *text, gui_text_rect_t *rect)
Text layout by mode.
- Parameters
text -- Widget pointer.
rect -- Widget boundary.
-
void gui_font_get_dot_info(gui_text_t *text)
Get dot information by utf-8 or utf-16.
- Parameters
text -- Widget pointer.
-
struct GUI_CHAR_HEAD
-
struct MEM_FONT_LIB
-
struct GUI_FONT_HEAD_BMP
Enums
Functions
-
uint16_t process_content_by_charset(TEXT_CHARSET charset_type, uint8_t *content, uint16_t len, uint32_t **p_buf_ptr)
Converts content from a specified charset to Unicode code points.
- Parameters
charset_type -- Charset type of the content.
content -- Input content to be converted.
len -- Length of the input content in bytes.
p_buf_ptr -- Pointer to the buffer that will hold the Unicode code points.
- Returns
Length of the Unicode code points array.
-
uint32_t get_len_by_char_num(uint8_t *utf8, uint32_t char_num)
Get the len by char num object.
- Parameters
utf8 -- UTF8 string pointer.
char_num -- Number of characters.
- Returns
Length of the UTF8 string in bytes.
-
uint32_t generate_emoji_file_path_from_unicode(const uint32_t *unicode_buf, uint32_t len, char *file_path)
Function to generate file path based on a given Unicode sequence.
- Parameters
unicode_buf -- Unicode buffer to generate file path from.
len -- Length of the Unicode buffer.
file_path -- Output file path buffer.
- Returns
Length of the generated file path.
-
bool content_has_ap_unicode(uint32_t *unicode_buf, uint32_t len)
Check if the content has any Arabic or Persian Unicode characters.
- Parameters
unicode_buf -- Unicode buffer to check.
len -- Length of the Unicode buffer.
- Returns
true If the content has any Arabic or Persian Unicode characters.
- Returns
false If the content does not have any Arabic or Persian Unicode characters.
-
bool content_has_ap(TEXT_CHARSET charset_type, uint8_t *content, uint16_t len)
Check if the content has any Arabic or Persian Unicode characters.
- Parameters
charset_type -- The charset type of the content.
content -- Input content to be checked.
len -- Length of the input content in bytes.
- Returns
true If the content has any Arabic or Persian Unicode characters.
- Returns
false If the content does not have any Arabic or Persian Unicode characters.
-
uint32_t process_ap_unicode(uint32_t *unicode_buf, uint32_t unicode_len)
Process Arabic or Persian Unicode characters in the content.
- Parameters
unicode_buf -- Unicode buffer to process.
unicode_len -- Length of the Unicode buffer.
- Returns
uint32_t The length of the processed Unicode buffer.
-
bool content_has_thai_unicode(uint32_t *unicode_buf, uint32_t len)
Check if the content has any Thai Unicode characters.
- Parameters
unicode_buf -- Unicode buffer to check.
len -- Length of the Unicode buffer.
- Returns
true If the content has any Thai Unicode characters.
- Returns
false If the content does not have any Thai Unicode characters.
-
bool content_has_thai(TEXT_CHARSET charset_type, uint8_t *content, uint16_t len)
Check if the content has any Thai Unicode characters.
- Parameters
charset_type -- The charset type of the content.
content -- Input content to be checked.
len -- Length of the input content in bytes.
- Returns
true If the content has any Thai Unicode characters.
- Returns
false If the content does not have any Thai Unicode characters.
-
uint32_t get_thai_mark_char_width(mem_char_t *chr, uint32_t char_count)
Get the width sum of mark Thai characters.
- Parameters
chr -- The memory character array.
char_count -- The count of characters.
- Returns
uint32_t The width sum of Thai characters.
-
uint32_t process_thai_char_struct(mem_char_t *chr, uint32_t unicode_len, THAI_MARK_INFO **mark_array_out, uint32_t *mark_count_out)
Process Thai character struct.
- Parameters
chr -- The memory character array.
unicode_len -- The length of the Unicode buffer.
mark_array_out -- Pointer to the array that will hold the Thai mark information.
mark_count_out -- Pointer to the variable that will hold the count of Thai marks.
- Returns
uint32_t The length of the processed base Thai Unicode buffer.
-
uint32_t post_process_thai_char_struct(mem_char_t *chr, uint32_t base_count, uint32_t active_base, uint32_t mark_count, THAI_MARK_INFO *marks)
Post process Thai character struct.
- Parameters
chr -- The memory character array.
base_count -- The count of base Thai characters.
mark_count -- The count of mark Thai characters.
active_base -- The count of active base Thai characters.
marks -- The Thai mark information array.
- Returns
uint32_t Finally active length include base and mark.
-
bool content_has_hebrew_unicode(uint32_t *unicode_buf, uint32_t len)
Check if the content has any Hebrew Unicode characters.
- Parameters
unicode_buf -- Unicode buffer to check.
len -- Length of the Unicode buffer.
- Returns
true If the content has any Hebrew Unicode characters.
- Returns
false If the content does not have any Hebrew Unicode characters.
-
bool content_has_hebrew(TEXT_CHARSET charset_type, uint8_t *content, uint16_t len)
Check if the content has any Hebrew Unicode characters.
- Parameters
charset_type -- The charset type of the content.
content -- Input content to be checked.
len -- Length of the input content in bytes.
- Returns
true If the content has any Hebrew Unicode characters.
- Returns
false If the content does not have any Hebrew Unicode characters.
-
struct gui_text_rect_t
-
struct mem_char_t
-
struct ap_chars_map_t
-
struct THAI_MARK_INFO